GreenTを使うと、ニューラル機械翻訳の翻訳に用語集を適用できます。GreenTでは、案件用の用語集を最初に作成し、その用語集に基づいてニューラル機械翻訳をします。
この記事では、手持ちの用語集をニューラル機械翻訳に用いる方法を和文の特許明細書を用いて説明します。
仕組み
用語集を作成するために、まず所定のルールに基づいて原文から名詞句を自動的に抽出します。このルールは、名詞句の「使用頻度」と「文字列の長さ(英語であれば単語数、日本語であれば文字数)」です。これは、手持ちの用語集を使用しない用語集作りと同じです。
手持ちの用語集を用いる場合には、自動抽出される名詞句に加えて、用語集に記載のある用語をすべて抽出します。[Glossary Generator]ダイアログで用語集を用いる場合、この用語集内の「文書中で1回以上使用される用語」を抽出できます。固有名詞や物質名は使用頻度が少なくても重要ですので、手持ちの用語集を使えば確実に拾えます。
用語集には名詞句を登録するようにしてください。GreenTでは形容詞や動詞を用語集に登録しても、訳文に正確に反映できません。
手順
名詞句の抽出
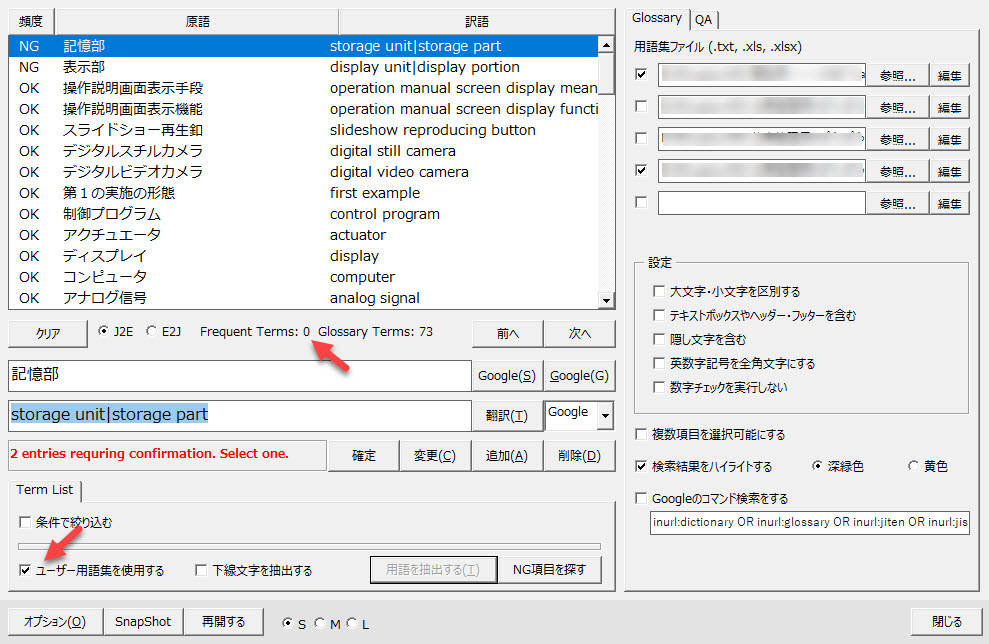
[アドイン]タブの[GG]ボタンをクリックして[Glossary Generator]ダイアログを開き、左下の[オプション]ボタンをクリックします。
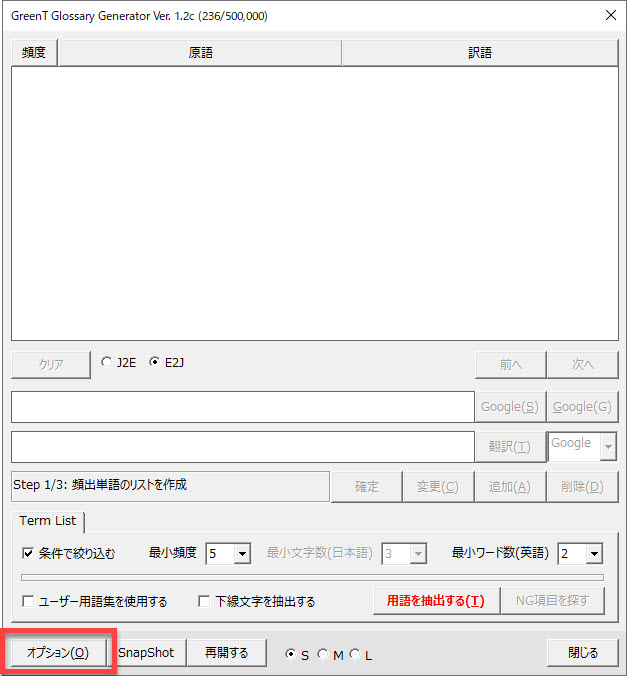
すると、[Glossary]タブに手持ちの用語集の設定画面が表示されます。ここにExcelファイルやテキストファイルで管理している用語集を登録します。使う用語集にチェックを入れます。
優先する用語集がある場合には上から順番に登録してください。
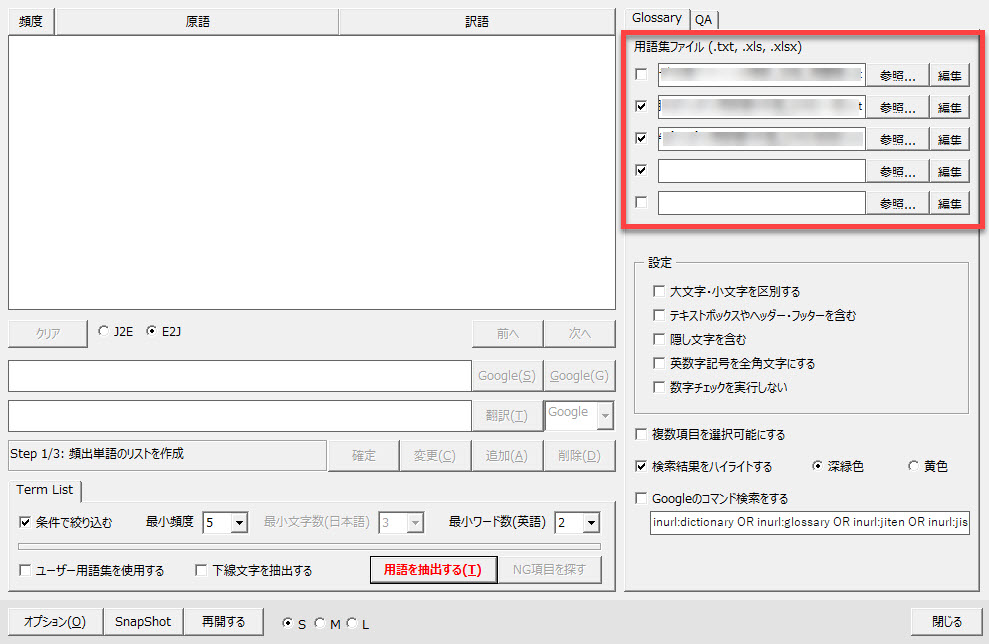
Excelファイルの用語集の場合、シート1(一番左側のシート)のみ読み込まれます。A列に原語、B列に訳語を記載してください。
テキストファイルの用語集の場合、タブ区切りで「原語」(タブ)「訳語」としてください。上書き翻訳で用いる用語集のように英訳語の末尾に半角スペースが入っていてもかまいません。入っていなくてもいいです。原語も訳語も、用語の先頭と末尾のスペースは自動的に削除されます。
用語集作成のヒント
以下のような記述は、用語として不適切なため修正してください。
| 原語 | 訳語 | 備考 |
| 基板(訳し分け必要) | substrate(半導体)|board(プリント基板など) | 原語にメモ書きがある用語集は使えません。検索ができません。削除してください。
訳語のメモは翻訳時に削除してもいいかもしれませんが。 (参考:複数の候補から訳語を選択する) |
| position|location | 位置 | 原語に縦棒(パイプ)を入れてもOR検索にはなりません。それぞれ別の項目として記入してください。
なお、positionやlocationは複合語になった場合に訳が変わりうるので、用語集へは登録しないことを強くお勧めします。 positionは位置だけではなく、「状態」のような訳語になることも場合もありえます。locationは「ロケーション」と訳される場合もあります。 |
| 毎年 | yearly | 副詞句は用語集に登録しないことをお勧めします。もし使用したい副詞句がある場合には、ポストエディットで修正してください。
たとえば、annuallyではなくyearlyを使用する場合には、この語句を変換するように登録します。文脈で判断が必要だと思いますので個別変換に登録してください。 (参考:ポストエディット) |
手持ちの用語集の訳語の特定
[用語集を使用する]をオンにすると、上記で設定した用語集を使えます。なお、用語集を使用する際に、[条件で絞り込む]もオンにすると、語句の使用頻度や文字数による用語抽出も同時に独立して実行できます。
つまり、[条件で絞り込む]による用語の抽出条件(頻度や語数、文字数)は、[用語集を使用する]による用語の抽出には適用されません。[用語集を使用する]では、用語集に記載があるものをすべて抽出します。会社名や製品名、化合物名など使用頻度が1回であっても重要な用語があるからです。
[用語を抽出する]ボタンをクリックして名詞句を抽出します。用語集から抽出された用語は[OK]と表示されます。
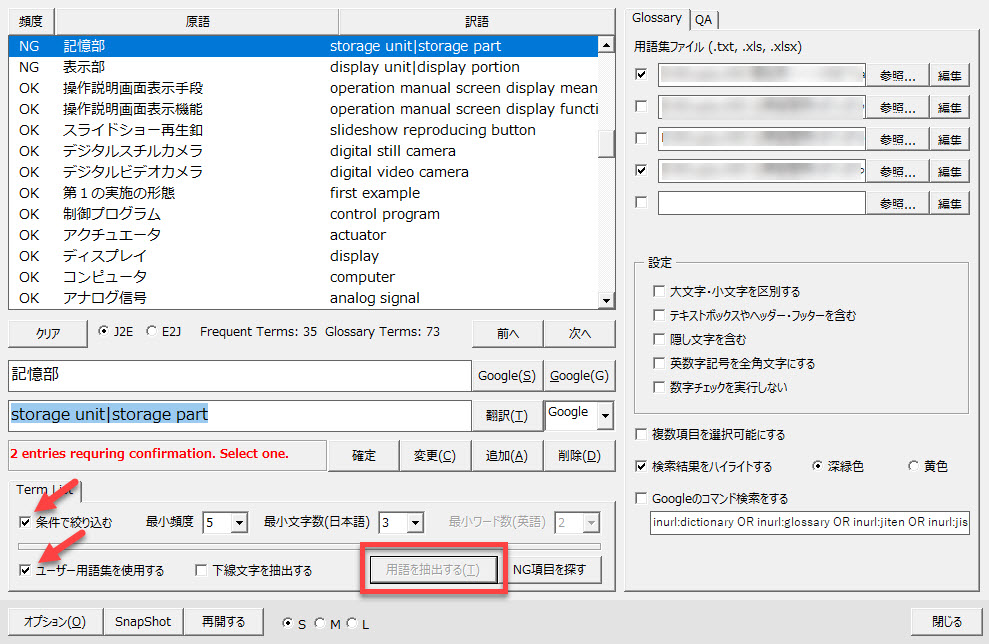
手持ちの用語集同士で訳語の揺れがない場合には、抽出された名詞句を確認します。今回の用語集では訳語の揺れ(複数の訳語がある場合)がいくつか見つかりました。
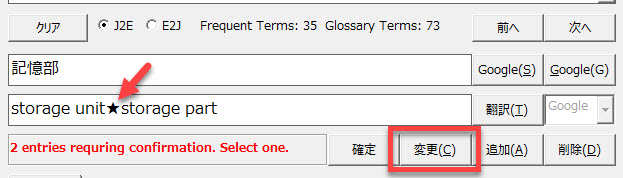
訳語の揺れが見つかると一覧表の左端に[NG]と表示されます。[NG]の場合には訳語を1つ選択しなければなりません。
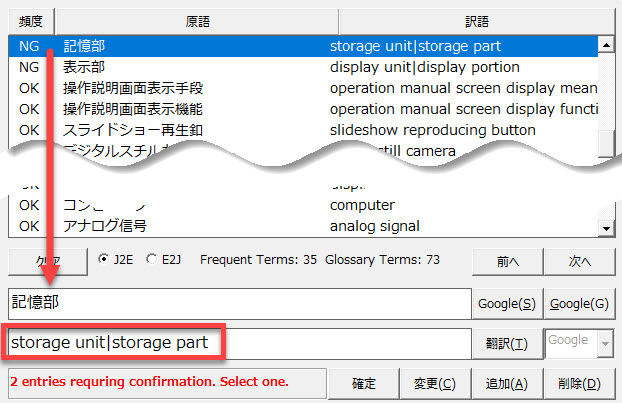
上記の例では、「記憶部」という原語に対して、「storage unit|storage part」と | で区切られた2つの訳語が表示されています。
個々の用語集で定義されていた言葉がすべて列挙されています。このときに、優先される用語集([Glossary]タブで上の方に登録されている用語集)の訳語が先に表示されますので、選択しやすいと思います。
今回はクライアントから指定された「storing unit」を使うことにします。修正後に、[変更]ボタンをクリックします。
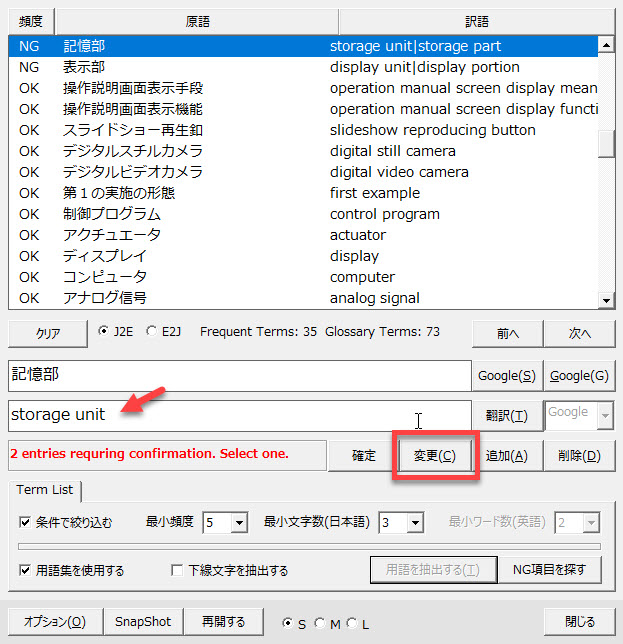
検出された[NG]の数だけ繰り返します。訳語内に | が残っていると、[NG]と判定されますので残さず削除してください。
訳語を1つに定められない場合でも仮訳を入力することをおすすめします。ここで訳語を特定しない場合には、ニューラル機械翻訳によって勝手な訳が翻訳の都度決められてしまうということです。
複数の訳語を登録する場合
この時点で1つの訳語に決められない場合には、[確定]ボタンをクリックします。以下のようにダイアログが表示されます。
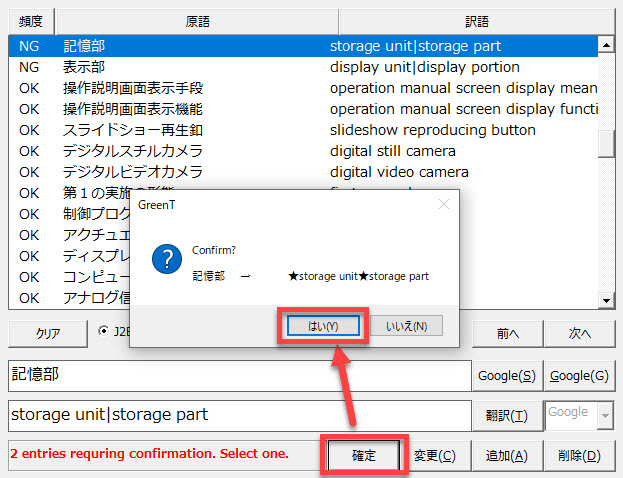
[はい]をクリックすると、以下のように変更されます。
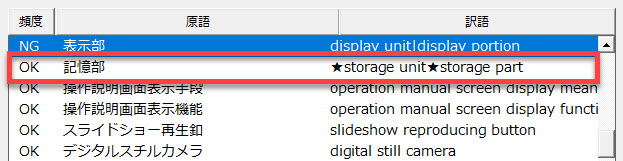
上記のようにすれば自動的に★マークで区切られますが、ご自身で「|」の記号を「★」などの専用のマーカーと置き換えてもいいです。訳文作成の際に、候補の中から1つ選択します。翻訳で使う場面をイメージして適宜調整してください。
(参考:複数の候補から訳語を選択する)
テキストファイルには最終的に以下のように保存されます。

なお、上記の例では、頻度や文字数による用語抽出も実行しました。用語集に記載のある用語だけを抽出する場合には、以下のように[条件で絞り込む]をオフにして[用語集を使用する]だけをオンにします。
確認
抽出された名詞句がすべて用語集にふさわしいとは限りません。そもそも訳語を特定できないような言葉が抽出されていることがあるからです。
手持ちの用語集を使用しない用語集作りでも説明したとおり、それぞれの名詞句を[前へ]ボタン([Previous]ボタン)と[次へ]ボタン([Next]ボタン)を用いて文書中でどのように使われているのか確認して用語集に入れるべき言葉なのかを検討してください。
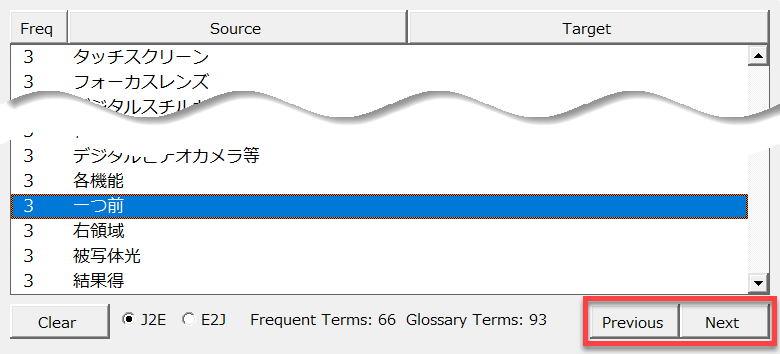
また、[原語]ボタン([Source]ボタン)をクリックすると抽出された原語をあいうえお順/ABC順に並べ替えられます。確認作業に使ってみてください。

なお、用語の数があればいいわけではありません。用語を定義しすぎるとニューラル機械翻訳の能力を生かし切れません。ニューラル機械翻訳で当たり前に出力できそうな用語(たとえば、サイズ、カードなど)はわざわざ用語集に登録しなくてもよいと思います。絶対に間違えたくない専門用語やクライアントからの指定用語以外はあまり力を入れすぎずに試してみてください。
(参考:出力された訳文の用語を修正する方法)
ここで登録した用語が後の機械翻訳に用いられてQAチェックにも使われます。
訳語の出力
準備ができたら訳語を出力します。[訳語を取得する]ボタンをクリックします。
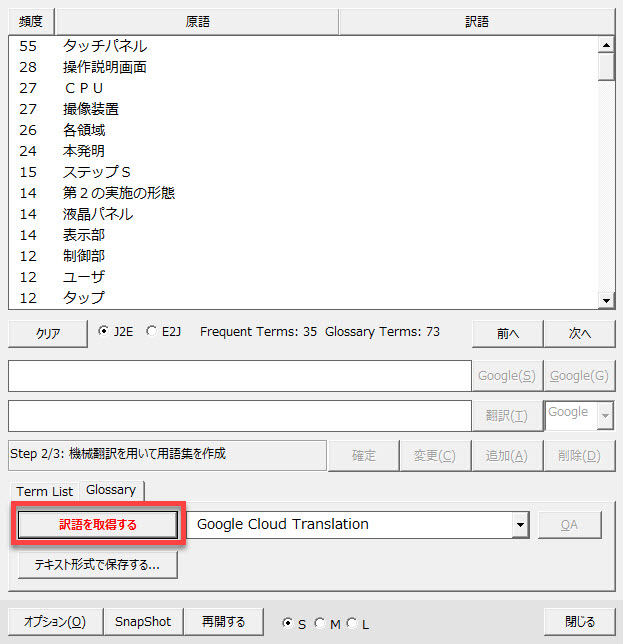
訳語が出力されると自動的に「QAチェック」が実行され、進捗状況がプログレスバーで表示されます。
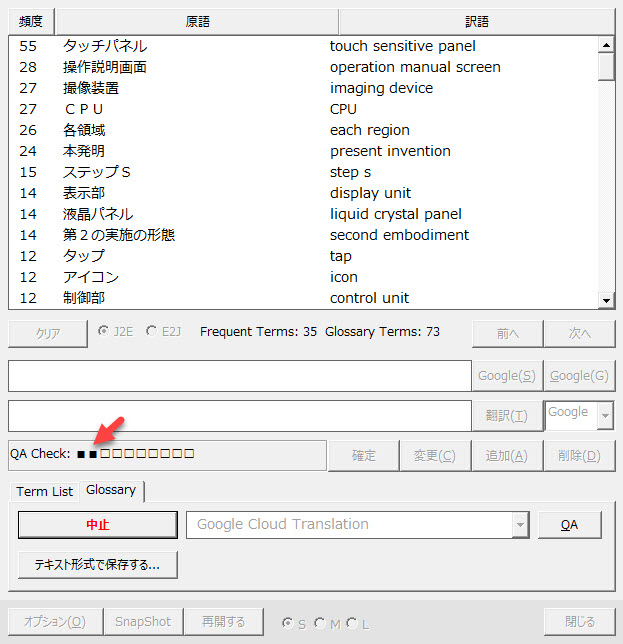
QAチェックでは、原語の数字と訳語の数字が間違っていないか、また手持ちの用語集で用いられている訳語([OK]が表示されている訳語)が別の訳語に反映されているか?をチェックします。
たとえば、「第2の実施の形態」で「third embodiment」の出力結果が得られた場合、以下のようにオプションの[QA]タブにQA結果が表示されます。
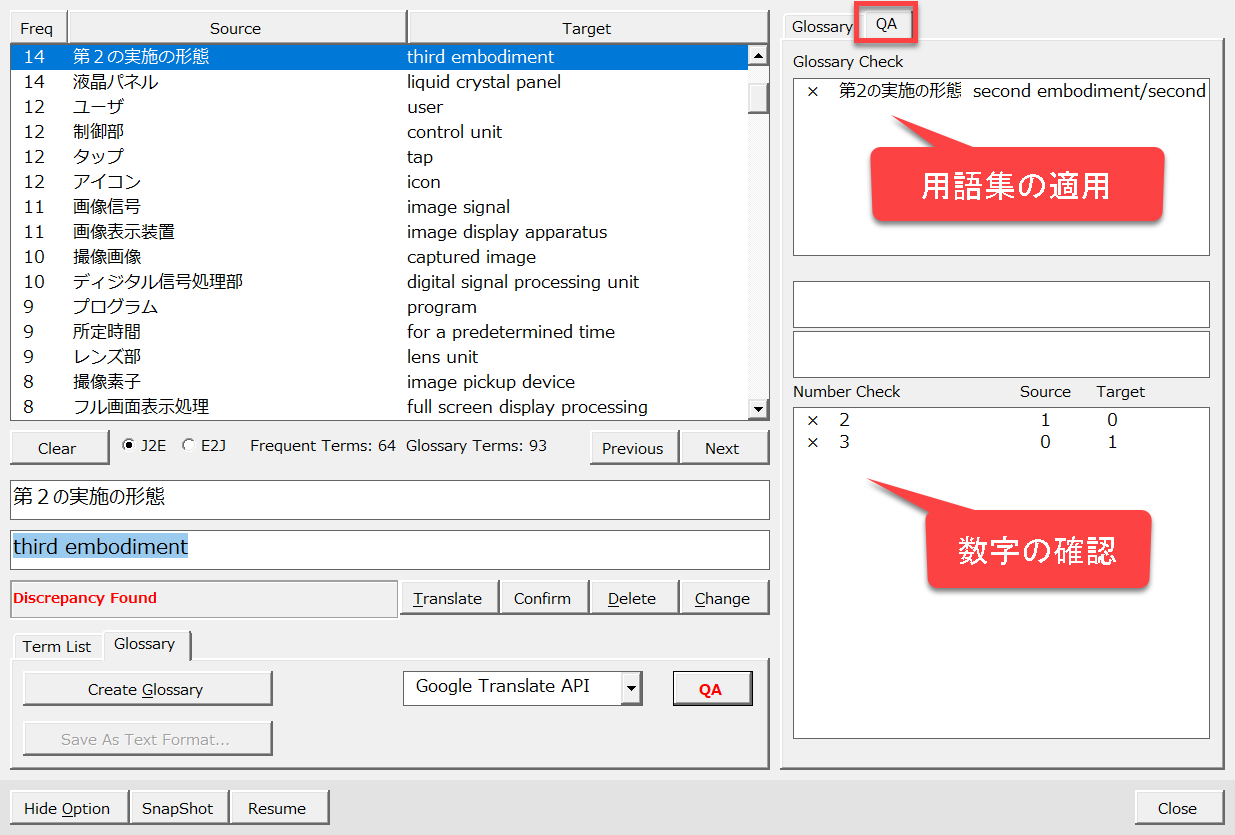
修正した後に[変更]ボタン([Change]ボタン)で確定し、[QA]ボタンをクリックしてQAチェックを続行します。エラーが出なくなるまで繰り返します。
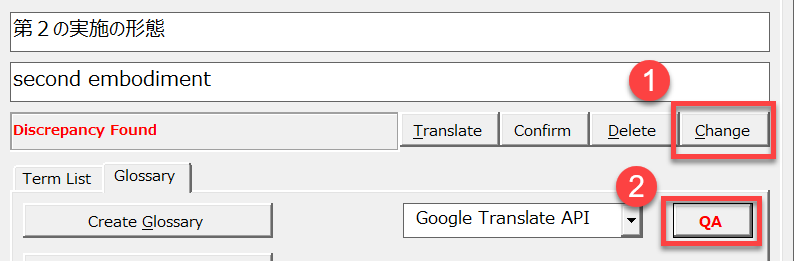
用語の適用エラーと判定されても正しい場合もあります。
たとえば、用語集で「変換部」を「converting unit」と定義しているときに、「A/D変換部」の訳語が「A / D converter」として出力された場合を想定します。この場合、「A/D変換部」における「変換部」が「converter」となっているので、「変換部」が正しく訳されていないとして確認が促されます。
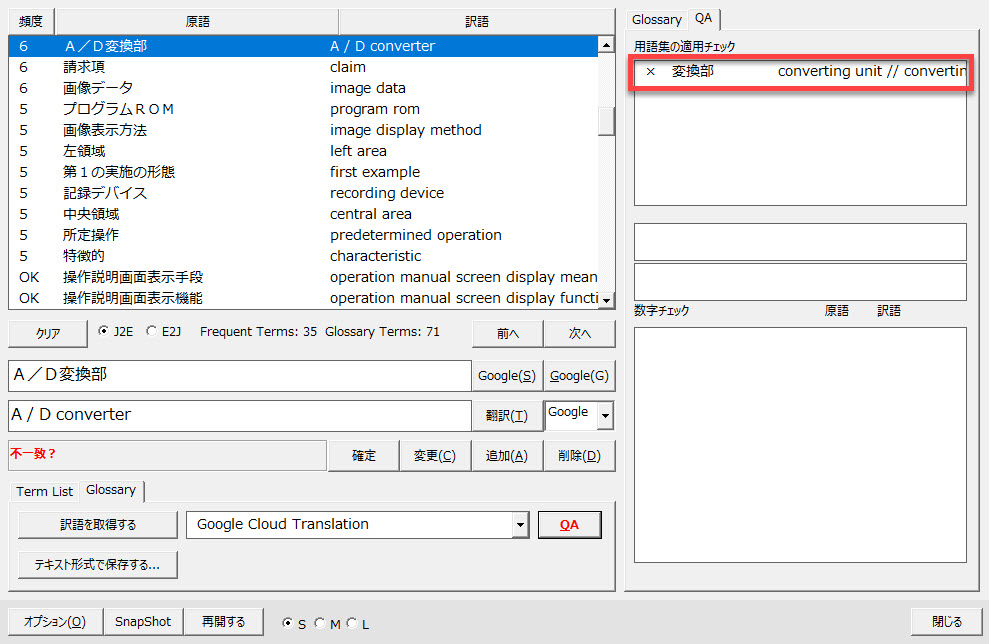
「A/D変換部」の訳語を「A / D converter」としてそのまま保持するのであれば、以下のように[確定]ボタンをクリックして確定してください。

すると、以下のように[OK] マークが付され、この項目はQAチェックの対象外となります。
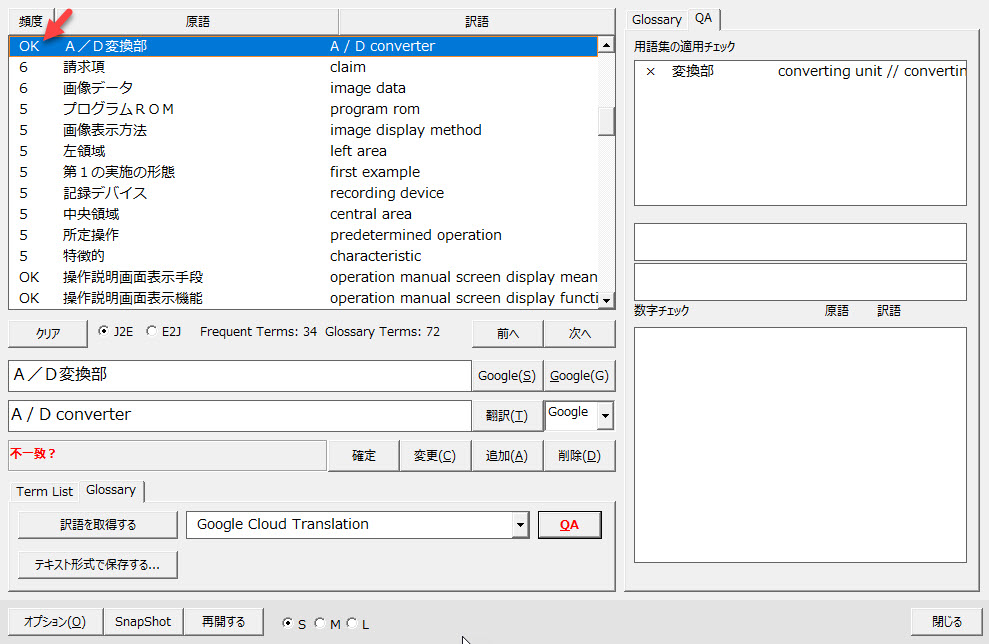
もし、「A/D converting unit」に変更する場合には、修正後に[変更]ボタンをクリックしてください。そして再度[QA]ボタンをクリックしてQAチェックを続行します。エラーが出なくなるまで繰り返します。
訳語の特定
このように機械的にチェックを実行できますが、出力された訳語が正しいとは限りません。
[前へ]ボタン([Previous]ボタン)と[次へ]ボタン([Next]ボタン)を用いて文章の中で実際にどのように用いられている用語なのか確認してください。
また[原語]ボタン([Source]ボタン)と[訳語]ボタン([Target]ボタン)を用いて用語を並べ替えてみて、必要に応じて他の用語との表記の統一をしてください。
用語集ファイルの保存
すべての訳語が決まったらファイルに出力します。テキスト形式で保存をします。翻訳で用いますので、わかりやすい場所に保存をしてください。